Shadow Data Remediation: A Step-by-Step Guide for Enterprise Security Teams
Bilal Khan
January 21, 2026
Discover, classify, and remediate shadow data with this enterprise guide. Learn masking, tokenization, and FPE techniques to eliminate hidden security risks.
Shadow data is sensitive information that exists outside your security controls. It accumulates in non-production environments, developer instances, SaaS applications, and cloud storage – creating compliance gaps and breach risk you can't see.
Remediating shadow data requires a structured approach: discover, classify, prioritize, and execute. This guide walks through each stage with practical techniques for enterprise security teams.
Key Takeaways
Shadow data remediation requires a structured, four-stage approach:
Discover all sensitive data outside governance controls.
Classify data by type, sensitivity, and compliance requirement.
Prioritize based on risk score, volume, and access levels.
Execute remediation using masking, tokenization, FPE, or deletion.
The right technique depends on your use case:
Masking for non-production environments.
Tokenization for compliance scope reduction and transactional data.
FPE for legacy systems with format requirements.
Deletion for obsolete data with no business value.
What is Shadow Data?
Shadow data is sensitive information that resides outside formal IT governance. It exists in systems, environments, and applications that security teams don't monitor or control.
Key characteristics:
Lives in non-production environments, test databases, and developer instances.
Flows into SaaS applications like Salesforce, Jira, and Google Drive.
Contains PII, PHI, and PCI data "in the clear."
Has no encryption, masking, or access controls.
Violates compliance requirements without anyone knowing.
Shadow data is different from dark data. Dark data is known but unused. Shadow data is unknown to central IT – created and stored without oversight.
Why Shadow Data Is a Critical Security Risk
Shadow data creates vulnerabilities across security, compliance, and operations.
Security Exposure
Unprotected shadow data is an easy target. Attackers don't need to breach production systems when non-production environments contain the same sensitive information without encryption or access controls.
Compliance Violations
Regulations like GDPR, HIPAA, and PCI DSS require strict controls over sensitive data. Shadow data violates these mandates by existing in environments without:
Required encryption.
Access logging.
Data residency controls.
Retention policies.
Organizations can't demonstrate compliance for data they don't know exists.
Operational Costs
Shadow data consumes storage, complicates data management, and creates inconsistent data quality. When a breach occurs, the cost of incident response and remediation far exceeds the cost of proactive management.
The Four Stages of Shadow Data Remediation
Effective remediation follows a structured process: discovery, classification, prioritization, and execution.
Stage 1: Discovery
You can't protect data you don't know exists. Discovery identifies all instances of sensitive data residing outside controlled environments.
Discovery methods:
Automated scanning tools: AI-powered platforms scan databases, file systems, cloud storage, and applications to identify sensitive data patterns.
Network traffic analysis: Monitor data in transit to SaaS applications. Network-layer solutions intercept and identify PII before it reaches third-party platforms.
Cloud service audits: Scan AWS RDS snapshots, Azure Blob storage, and GCP buckets. These often contain full copies of production data.
Endpoint scans: Identify sensitive data stored locally on workstations and laptops.
DataStealth's data discovery capabilities scan environments at scale—including petabyte-sized databases with billions of rows.
Discovery challenges:
Volume: Petabytes of data across hundreds of systems.
Velocity: New data generated and replicated continuously.
Classification assigns context and risk levels to discovered data. It answers: What is this data, how sensitive is it, and what regulations apply?
Classification categories:
Category
Examples
Data Type
PII, PHI, PCI, intellectual property, financial records
Sensitivity Level
Public, internal, confidential, restricted
Regulatory Requirement
GDPR, CCPA, HIPAA, PCI DSS, SOC 2
Business Impact
Critical, high, medium, low
DataStealth provides automated data classification that categorizes data by type, sensitivity, and compliance requirement.
Classification approach:
Use automated tools for speed and consistency.
Apply human oversight for edge cases.
Define classification rules in data governance policies.
Stage 3: Prioritization
Resource constraints make it impossible to remediate all shadow data simultaneously. Prioritization focuses effort on the highest-risk data first.
Prioritization factors:
Risk score: Composite of sensitivity, exposure, and breach impact.
Data volume: Larger volumes of sensitive data carry higher liability.
Access levels: Broad access by developers or third parties increases risk.
Compliance mandates: PCI and HIPAA violations demand urgent remediation.
Data location: Distributed data across multiple SaaS applications is harder to secure.
Risk prioritization matrix:
Sensitivity
Limited Access
Broad Internal Access
External Access
Low
Low priority
Medium priority
Medium priority
Medium
Medium priority
High priority
Critical priority
High
High priority
Critical priority
Immediate action
Stage 4: Execution
Execute remediation using techniques matched to the data type, environment, and risk level.
Shadow Data Remediation Techniques
Multiple techniques address shadow data. The right choice depends on whether data needs to be anonymized, encrypted, or deleted.
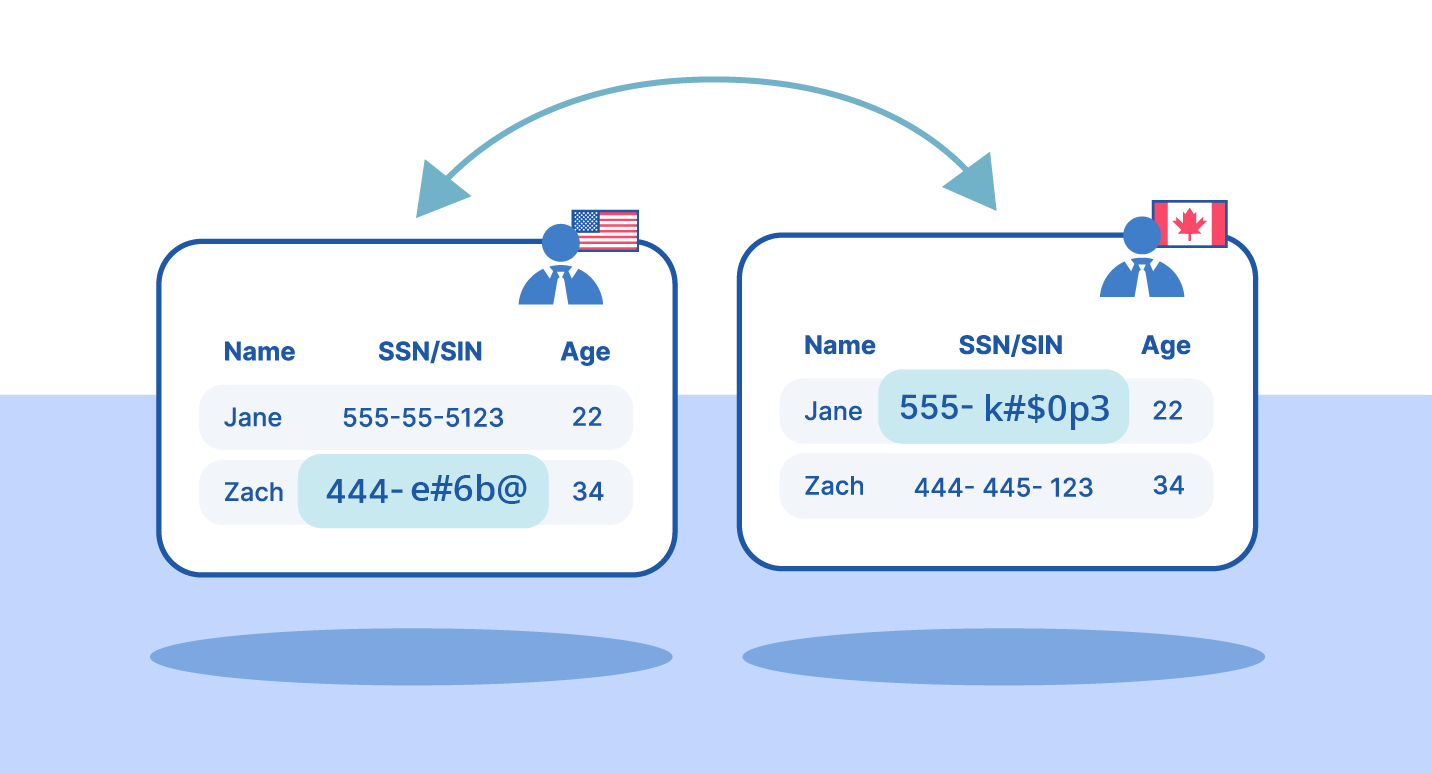
Data Masking
Data masking replaces sensitive values with realistic but fictitious data. The original data cannot be recovered.
Key characteristics:
Irreversible transformation.
Preserves data format and structure.
Ideal for non-production environments.
Enables realistic testing without real PII.
Example:
Dynamic Masking Example
Use masking for development, testing, analytics, and training environments.
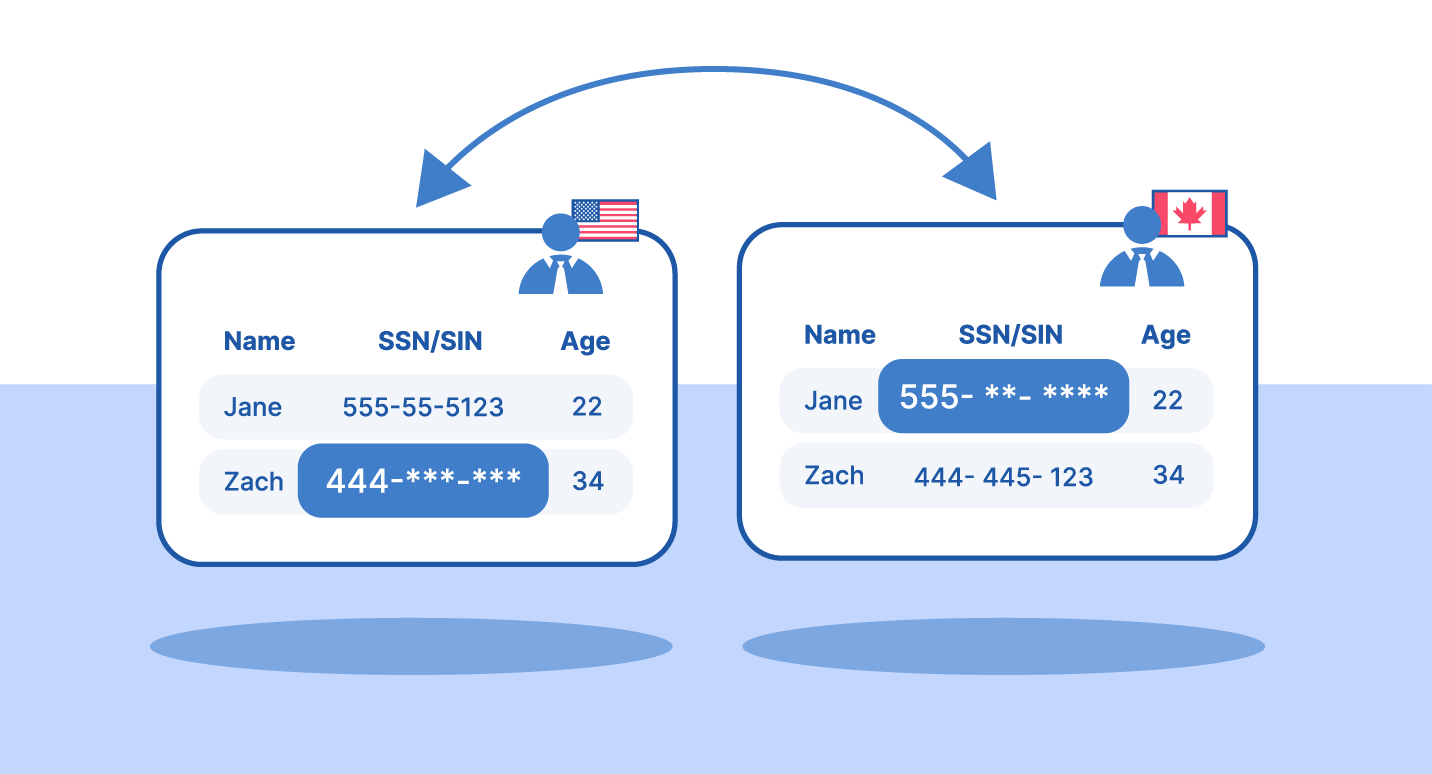
Tokenization
Tokenization replaces sensitive data with a non-sensitive token. The original data is stored in a secure vault. The token has no mathematical relationship to the original value.
Key characteristics:
Reversible with vault access.
Token is meaningless if stolen.
Removes data from compliance scope.
Supports transactional workflows.
Tokenization Example
Deterministic tokenization ensures the same input always produces the same token across all systems. This maintains referential integrity in distributed environments. Joins, deduplication, and analytics continue to work without exposing real data.
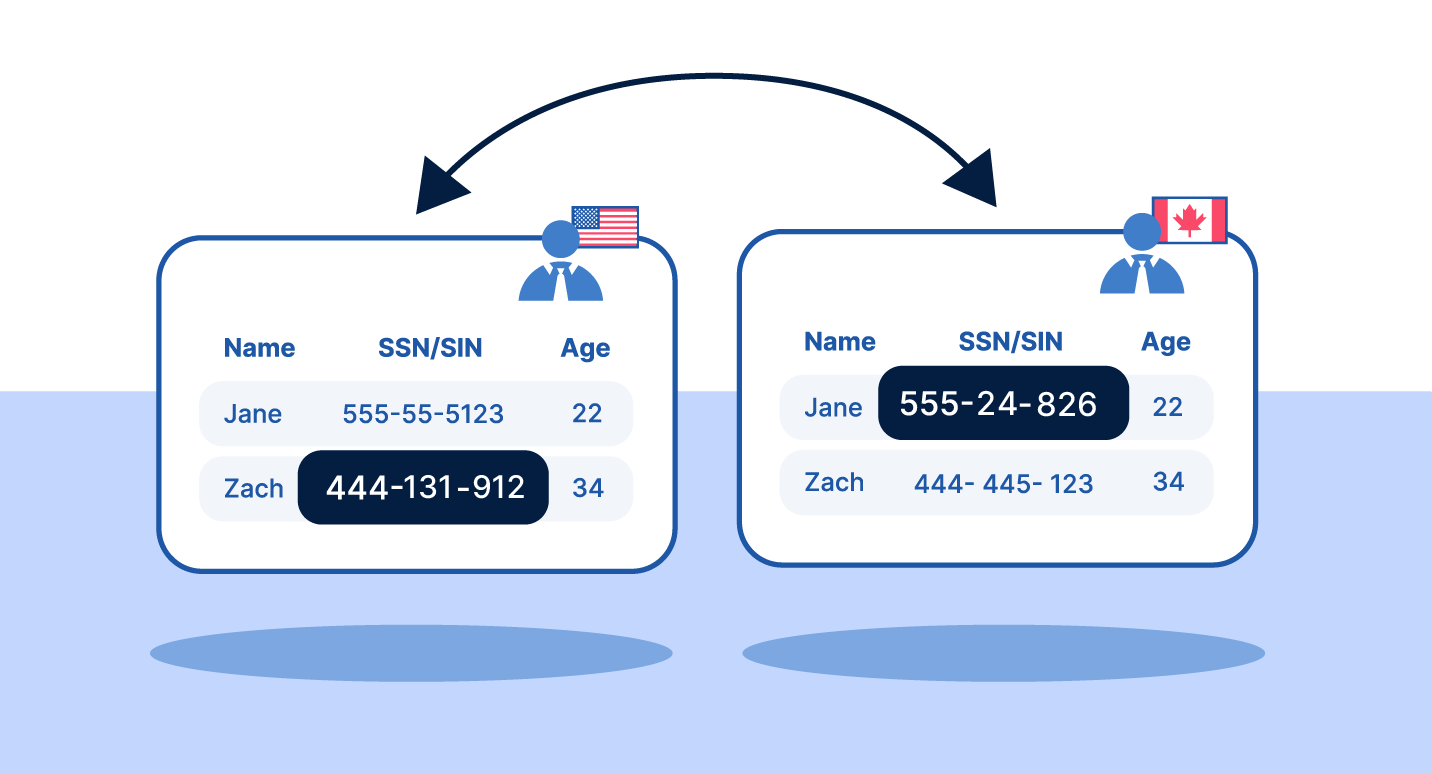
Format Preserving Encryption (FPE)
Format-Preserving Encryption encrypts data while preserving its original format. A 16-digit credit card number remains 16 digits after encryption.
Key characteristics:
Reversible with decryption key.
Preserves data format and length.
No application changes required.
CPU-accelerated for high performance.
Format Preserving Tokenization
Use FPE when systems require specific data formats and re-identification is rare.
Deletion
For data that is obsolete, no longer legally required, or has no business value—delete it. Deletion is the most definitive remediation.
Access Control
Implement role-based access control (RBAC) and least privilege principles. Restrict access to sensitive data based on job function and necessity.
Data Masking vs Tokenization vs FPE: Side-by-Side
Feature
Data Masking
Tokenization
Format Preserving Encryption
Reversible
No
Yes (with vault)
Yes (with key)
Format preserved
Yes
Sometimes
Yes
Performance
Batch process
Slower (vault lookup)
Fast (CPU-accelerated)
Referential integrity
Challenging
Yes (deterministic)
Yes
Compliance scope
Removed
Removed
Data still sensitive
Primary use case
Non-production
Transactions, PCI compliance
Legacy systems
When Should You Use Each Technique?
Use Data Masking When:
Protecting non-production environments.
Enabling developers and testers to work with realistic data.
Data never needs to be reversed to original values.
Building analytics and training datasets.
Use Tokenization When:
Reducing PCI DSS or HIPAA compliance scope.
Protecting data in transactional workflows.
Maintaining referential integrity across distributed systems.
Data occasionally needs to be de-tokenized for authorized use.
Use FPE When:
Legacy systems require specific data formats.
High-throughput processing is critical.
Re-identification is rarely or never needed.
Encryption performance matters more than compliance scope reduction.
Use Deletion When:
Data is obsolete or has no business value.
Legal retention periods have expired.
Storage costs outweigh any potential utility.
Risk elimination is the priority.
Addressing Shadow Data in SaaS Applications
Shadow data doesn't stay in databases. It flows into Salesforce, Jira, Slack, Google Drive, and dozens of other SaaS applications. Customer support tickets contain PII. Project management tools store confidential data. File shares accumulate sensitive documents.
Traditional data protection approaches struggle with SaaS sprawl. API integrations are slow to build and maintain. Each application requires custom configuration.
DataStealth solves this with a network-layer architecture. It sits inline between your network and cloud providers, intercepting and scrubbing sensitive data in transit before it lands in third-party platforms.
Benefits:
No API integrations required for each SaaS application.
Protects data in HTTP/HTML traffic automatically.
Addresses data residency and security without application changes.
Enterprise environments contain petabytes of data across thousands of systems. A single table might hold 2.5 billion rows of PII. Refresh processes can take 48 hours.
Remediation at this scale requires:
Horizontal Scalability
The platform must process data concurrently across multiple compute resources. Serial processing of billions of rows creates unacceptable bottlenecks.
Parallel Processing
Concurrent row processing and parallelization across multiple smaller tables accelerates remediation. DataStealth ingests and egresses data chunks in parallel.
Cloud Workflow Integration
AWS RDS snapshots hydrate slowly from S3. Remediation tools must integrate with these specific workflows, not fight against them.
Performance Metrics
Technical architects demand specific latency numbers. Know the performance characteristics of FPE operations, token lookups, and data masking at your expected volumes.
Shadow Data in Non-Production Environments
Non-production environments are the largest source of shadow data. Developers and testers need realistic data to validate applications. The easiest approach is copying production data, which exposes real PII to people who don't need it.
Mask production data before it reaches non-production systems.
Maintain data relationships and format for realistic testing.
Eliminate PII exposure to developers, contractors, and third parties.
No application changes required.
Continuous Shadow Data Governance
Remediating existing shadow data is not a one-time fix. New shadow data emerges continuously as:
Developers create new test environments.
Employees share data through new SaaS tools.
Cloud services proliferate across the organization.
Third-party integrations expand.
Continuous governance requires:
Automated Discovery
Run discovery scans continuously. Identify new shadow data as it appears, not months later during an audit.
Policy Enforcement
Automate protection based on classification. When sensitive data is detected, apply masking, tokenization, or access controls automatically.
Access Reviews
Regularly review who has access to sensitive data. Revoke unnecessary permissions. Enforce least privilege.
Monitoring and Alerting
Track shadow data volume, risk scores, and remediation progress. Alert on new high-risk discoveries.
Metrics That Matter
Reduction in shadow data volume.
Closure of compliance gaps.
Decrease in exposed sensitive data instances.
Improvement in overall risk scores.
How DataStealth Addresses Shadow Data Challenges
DataStealth directly solves the technical challenges of shadow data remediation:
Challenge
DataStealth Solution
Petabyte-scale data
Horizontal scalability with concurrent processing
AWS snapshot workflows
Native integration with RDS snapshot hydration
SaaS data sprawl
Network-layer interception without API integrations
Referential integrity
Deterministic tokenization across distributed systems
Legacy systems
Format Preserving Encryption without code changes
Operational burden
No-code, no-agents, no-collectors architecture
DataStealth integrates with mainframes, AWS, Azure, GCP, SAP, and third-party SaaS applications. Its data protection capabilities scale across complex hybrid environments.
Continuous governance prevents shadow data from re-accumulating. Automated discovery, policy enforcement, and access reviews sustain long-term security.
Platforms like DataStealth address the hardest challenges: petabyte-scale volumes, SaaS sprawl, and complex cloud workflows – without agents, code changes, or custom integrations.
Frequently Asked Questions
This section addresses common questions about shadow data, its risks, and how organizations can govern and remediate it.
1. What is shadow data?
Shadow data is sensitive information that exists outside formal IT and security governance. It typically resides in non-production environments, SaaS applications, cloud storage, or ad-hoc workflows without proper security controls, encryption, or access management.
2. What is the difference between shadow data and dark data?
Dark data refers to information that organizations knowingly collect and store but never use. Its existence is known, even if its value is unclear. Shadow data, by contrast, is unknown to central IT and security teams and is created or stored without oversight, governance, or approval.
3. Why is shadow data a compliance risk?
Shadow data often contains regulated information such as PII, PHI, or PCI data that is not protected by required security controls. Because organizations cannot demonstrate compliance for data they do not know exists, shadow data creates violations of GDPR, HIPAA, PCI DSS, and other regulatory frameworks.
4. What is deterministic tokenization?
Deterministic tokenization ensures that the same sensitive value always maps to the same token across all systems. For example, the name “Jane Smith” consistently becomes the same token everywhere. This preserves referential integrity for joins, analytics, and reporting without exposing real sensitive data.
5. When should I use format-preserving encryption (FPE) instead of tokenization?
Format-preserving encryption is best used when systems require strict data formats (such as 16-digit credit card numbers), when re-identification is rarely required, and when performance is critical. FPE is hardware-accelerated and often faster than tokenization for one-way or high-throughput data flows.
6. How does DataStealth handle shadow data in SaaS applications?
DataStealth uses a network-layer architecture to intercept data in transit before it reaches SaaS platforms. It scrubs sensitive data from HTTP and HTML traffic without requiring individual API integrations, providing broad coverage across applications such as Salesforce, Jira, Slack, and other SaaS tools.
7. What are the operational requirements for shadow data remediation tools?
Key operational considerations include the ability to scale to petabyte-sized datasets, integration with cloud workflows such as AWS RDS snapshots, measurable performance for FPE and tokenization operations, and minimal ongoing maintenance requirements. No-code, agentless architectures significantly reduce operational burden.
8. How do I prevent shadow data from re-accumulating?
Preventing shadow data requires continuous governance rather than a one-time cleanup. Best practices include automated discovery scans, policy-based protection enforcement, regular access reviews, and real-time monitoring dashboards. Shadow data is an ongoing operational challenge that must be managed continuously.
About the Author:
Bilal Khan
Bilal is the Content Strategist at DataStealth. He's a recognized defence and security analyst who's researching the growing importance of cybersecurity and data protection in enterprise-sized organizations.